



SAN FRANCISCO, June 04, 2025 (GLOBE NEWSWIRE) — Today, MLCommons® announced new results for the MLPerf® Training v5.0 benchmark suite, highlighting the rapid growth and evolution of the field of AI. This round of benchmark results includes a record number of total submissions, as well as increased submissions for most benchmarks in the suite compared to the v4.1 benchmark.
MLPerf Training v5.0 introduces new Llama 3.1 405B benchmark
The MLPerf Training benchmark suite comprises full system tests that stress models, software, and hardware for a range of machine learning (ML) applications. The open-source and peer-reviewed benchmark suite provides a level playing field for competition that drives innovation, performance, and energy efficiency for the entire industry.
Version 5.0 introduces a new large language model pretraining benchmark based on the Llama 3.1 405B generative AI system, which is the largest model to be introduced in the training benchmark suite. It replaces the gpt3-based benchmark included in previous versions of the MLPerf Training benchmark suite. An MLPerf Training task force selected the new benchmark because it is a competitive model representative of the current state-of-the-art LLMs, including recent algorithmic updates and training on more tokens. More information on the new benchmark can be found here. Despite just being introduced, the Llama 3.1 405B benchmark is already receiving more submissions than the gpt3-based predecessor saw in previous rounds – demonstrating the popularity and importance of large-scale training.
Rapid performance improvements for key training scenarios
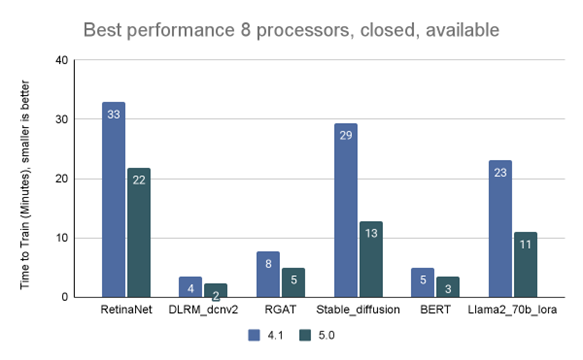
The MLPerf Training working group regularly adds emerging training workloads to the benchmark suite to ensure that it reflects industry trends. The Training 5.0 benchmark results show notable performance improvements for newer benchmarks, indicating that the industry is prioritizing emerging training workloads over older ones. The Stable Diffusion benchmark saw a 2.28x speed increase for 8-processor systems compared to the 4.1 version six months ago, and the Llama 2.0 70B LoRA benchmark increased its speed 2.10x versus version 4.1; both outpacing historical expectations for computing performance improvements over time as per Moore’s Law. Older benchmarks in the suite saw more modest performance improvements.

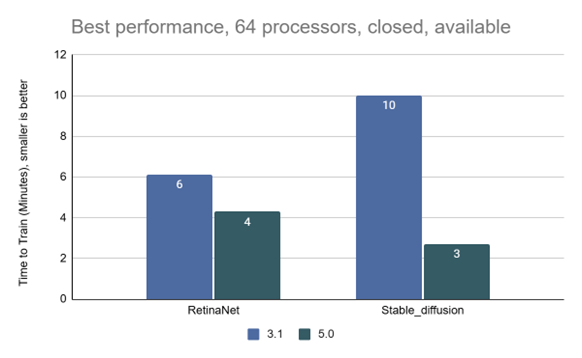
On multi-node, 64-processor systems, the RetinaNet benchmark saw a 1.43x speedup compared to the prior v3.1 benchmark round (the most recent to include comparable scale systems), while the Stable Diffusion benchmark had a dramatic 3.68x increase.

“This is the sign of a robust technology innovation cycle and co-design: AI takes advantage of new systems, but the systems are also evolving to support high-priority scenarios,” said Shriya Rishab, MLPerf Training working group co-chair.
Increasing diversity of processors, increasing scale of systems, broadening ecosystem
Submissions to MLPerf Training 5.0 utilized 12 unique processors, all in the available (production) category. Five of the processors have become publicly available since the last version of the benchmark suite.
- AMD Instinct MI300X 192GB HBM3
- AMD Instinct MI325X 256GB HBM3e
- NVIDIA Blackwell GPU (GB200)
- NVIDIA Blackwell GPU (B200-SXM-180GB)
- TPU-trillium
Submissions also included three new processor families:
- 5th Generation AMD Epyc Processor (“Turin”)
- Intel Xeon 6 Processor (“Granite Rapids”)
- Neoverse V2 as part of NVIDIA GB200
In addition, the number of multi-node systems submitted increased more than 1.8x when compared to version 4.1.
“The picture is clear: AI workloads are scaling up, systems are scaling up to run them, and hardware innovation continues to boost performance for key scenarios,” said Hiwot Kassa, MLPerf Training working group co-chair. “In-house large scale systems were built by few companies, but the increased proliferation – and competition – in AI-optimized systems is enabling the broader community to scale up their own infrastructure. Most notably, we see an increasing cadre of cloud service providers offering access to large-scale systems, democratizing access to training large models.
“The industry is not standing still, and neither can we. MLCommons is committed to continuing to evolve our benchmark suite so that we can capture and report on the innovation that is happening in the field of AI.”
Record industry participation
The MLPerf Training v5.0 round includes 201 performance results from 20 submitting organizations: AMD, ASUSTeK, Cisco Systems Inc., CoreWeave, Dell Technologies, GigaComputing, Google Cloud, Hewlett Packard Enterprise, IBM, Krai, Lambda, Lenovo, MangoBoost, Nebius, NVIDIA, Oracle, Quanta Cloud Technology, SCITIX, Supermicro, and TinyCorp.
“We would especially like to welcome first-time MLPerf Training submitters AMD, IBM, MangoBoost, Nebius, and SCITIX,” said David Kanter, Head of MLPerf at MLCommons. ”I would also like to highlight Lenovo’s first set of power benchmark submissions in this round – energy efficiency in AI training systems is an increasingly critical issue in need of accurate measurement.”
MLPerf Training v5.0 set a new high-water mark for the >200 submissions. The vast majority of the individual benchmark tests that carried over from the previous round saw an increase in submissions.
Robust participation by a broad set of industry stakeholders strengthens the AI/ML ecosystem as a whole and helps to ensure that the benchmark is serving the community’s needs. We invite submitters and other stakeholders to join the MLPerf Training working group and help us continue to evolve the benchmark.
View the results
To view the full results for MLPerf Training v5.0 and find additional information about the benchmarks, please visit the Training benchmark page.
About ML Commons
MLCommons is the world’s leader in AI benchmarking. An open engineering consortium supported by over 125 members and affiliates, MLCommons has a proven record of bringing together academia, industry, and civil society to measure and improve AI. The foundation for MLCommons began with the MLPerf benchmarks in 2018, which rapidly scaled as a set of industry metrics to measure machine learning performance and promote transparency of machine learning techniques. Since then, MLCommons has continued using collective engineering to build the benchmarks and metrics required for better AI – ultimately helping to evaluate and improve AI technologies’ accuracy, safety, speed, and efficiency.
For additional information on MLCommons and details on becoming a member, please visit MLCommons.org or email participation@mlcommons.org.
Press Inquiries: contact press@mlcommons.org
Photos accompanying this announcement are available at
https://www.globenewswire.com/NewsRoom/AttachmentNg/25f6643c-9978-4344-8c45-75336a9497dd
https://www.globenewswire.com/NewsRoom/AttachmentNg/7781c2e5-02ce-4b69-b92b-c12c7e3a48fd
![]()
Wall St Business News, Latest and Up-to-date Business Stories from Newsmakers of Tomorrow
